"Informed AI News" is an publications aggregation platform, ensuring you only gain the most valuable information, to eliminate information asymmetry and break through the limits of information cocoons. Find out more >>
Meta's Transfusion Model: Merging Transformer and Diffusion for Multimodal AI
- summary
- score




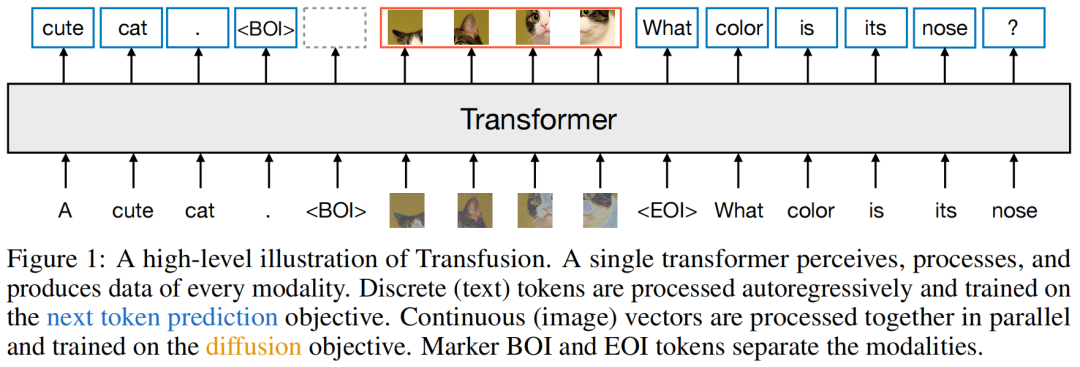
Meta's new Transfusion model merges Transformer and Diffusion techniques, aiming for a unified text and image generation system. This integration promises a significant step towards true multimodal AI.
Transfusion combines language modeling (predicting next text tokens) with diffusion (generating images) within a single Transformer framework. It pre-trains on mixed text and image data, scaling effectively in both single and multimodal benchmarks.
Key innovations include global causal attention for text and bidirectional attention within images, enhancing performance and compression. Transfusion's ability to generate high-quality images and maintain robust text capabilities sets it apart.
Experiments show Transfusion outperforms models like DALL-E 2 and Stable Diffusion XL in image generation. It also excels in image editing and text generation, demonstrating versatility and efficiency.
This advancement suggests a future where AI seamlessly handles various data types, from text to video, opening new possibilities in content creation and interaction.
| Scores | Value | Explanation |
|---|---|---|
| Objectivity | 6 | Comprehensive reporting and in-depth analysis. |
| Social Impact | 5 | Significantly influencing public opinion. |
| Credibility | 5 | Solid evidence from authoritative sources. |
| Potential | 6 | Inevitably leading to significant changes. |
| Practicality | 5 | Widely applied in practice with good results. |
| Entertainment Value | 3 | Can attract a portion of the audience. |